How to Think of Pandas Data Visualization If You’re Coming From Excel
This article is originally published in this...

Previously, I watched and blogged about the End-to-End Data Engineering Project course at Linkedin Learning. The course is very practical and shows how to build a data pipeline using modern tools and techniques.
Now, there’s another Linkedin Learning tutorial that dives deeper about dbt - the Data Engineering with DBT course.
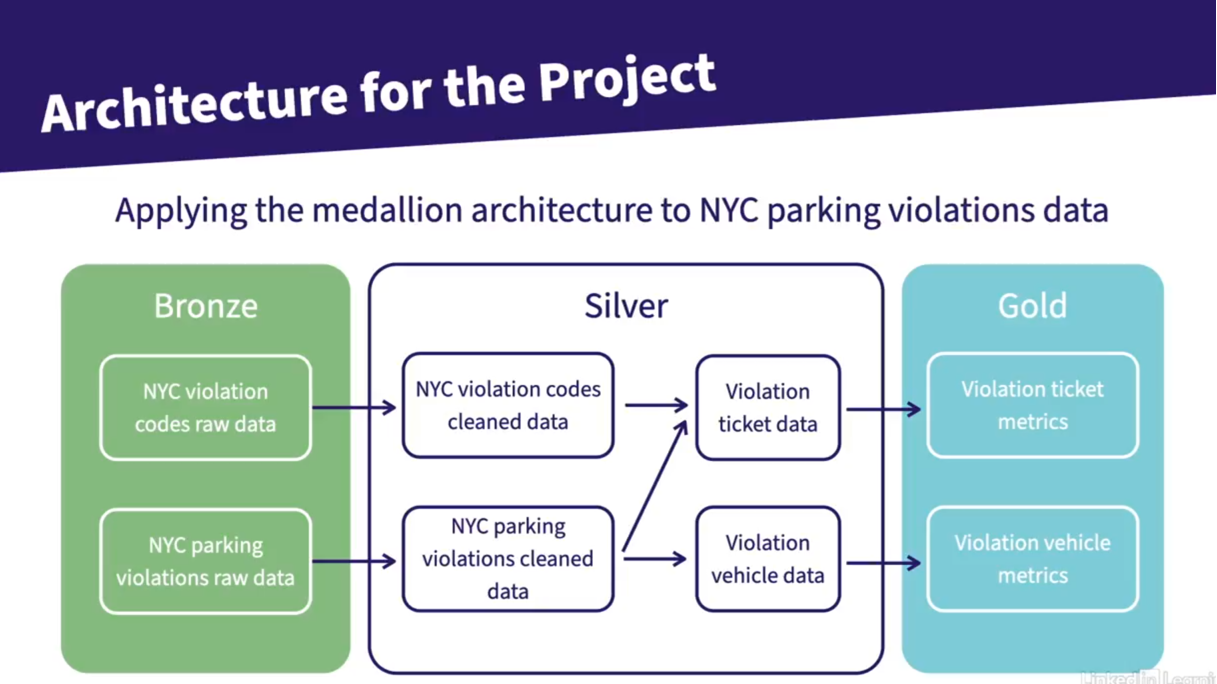
The course project centers around the creation of data models using the NYC DOF Parking Violation Codes dataset. This dataset is huge so the course uses only a sample of the dataset.
The course uses the Python and SQL inside a Github workspace to show the use of dbt in building the data models. In addition, it also showed how to use Github Actions to automate deployment of the data architecture.
What I like about this course is that it tackles the following aspects in building a data architecture
Testing - the course also showed how to test or validate your data when building a data architecture. In my experience, this is critical as it may point out to operational issues in the business. For example, a test can be made to point out any invoice that changed amounts after a week. An invoice that changed amount after a week may signify returns that were made outside the allowed return period, items that were shipped after an invoice was paid, or worse, collusion and theft among employees.
Documentation - the course also showed how to create a maintainable documentation for the data models. In my experience, lack of documentation can result to duplication of SQL queries as a new analyst tries to understand existing architecture, employees keeping copies of outdated information as they may find accessing the data cumbersome and confusing, and reports containing different values for the same KPI or measure as they may use different filters or criteria for the latter.
Deployment - the course also showed how to use Github Actions in order to automate deployments of data models. This is also critical in actual practice. Lack of automated deployments can results to wrong information as outdated data is used, and worse, making decisions based on this information.
I really enjoyed the course. The course solidified my understanding of DBT and I’m confident to use it on my next projects. I’m looking for ways to apply my learnings in building data architectures on the cloud using dbt.
This article is originally published in this...
This article is originally published in this...
This article is originally published in this...
Background As I’m looking for ways to learn mo...